Assignment 02: GPU Architecture and cuTile
The file assignments/02_assignment/src/__main__.py contains the main function that runs all the tasks for this assignment. Each task is implemented in a separate file in the same directory. The results of each task are printed to the console when the main function is executed.
Task 1: GPU Device Properties
import cupy as cp
def main():
print("CUDA Device Attributes:" )
for key, value in cp.cuda.Device().attributes.items():
if key in ["L2CacheSize", "MaxSharedMemoryPerMultiprocessor", "ClockRate"]:
print(f"\t{key}: {value}")
if __name__ == "__main__":
main()
Output:
CUDA Device Attributes:
ClockRate: 2418000
L2CacheSize: 25165824
MaxSharedMemoryPerMultiprocessor: 102400
Task 2: Matrix Reduction Kernel
a) cuTile kernel that reduces a 2D input matrix of arbitrary shape (M, K) along its last dimension (K)
import torch
import cuda.tile as ct
import math
def main():
M = 65
K = 33
# Calculate the next power of two for K
TILE_K = int(2**math.ceil(math.log2(K)))
A = torch.randn(M, K, device='cuda')
A_reduced = torch.empty(M, device='cuda')
grid = (M,)
# Launch kernel, passing TILE_K as the constant
ct.launch(torch.cuda.current_stream().cuda_stream,
grid,
matrix_reduce,
(A, A_reduced, TILE_K))
expected = torch.sum(A, dim=1)
assert torch.allclose(A_reduced, expected), "Task 2 failed: A_reduced does not match expected result!"
@ct.kernel
def matrix_reduce(A, A_reduced, TILE_K: ct.Constant[int]):
pid = ct.bid(0)
# Use the power-of-two TILE_K for the shape.
# The padding mode handles the difference between K (33) and TILE_K (64).
A_row = ct.load(
A,
index=(pid, 0),
shape=(1, TILE_K),
padding_mode=ct.PaddingMode.ZERO
)
result = ct.sum(A_row, axis=1)
ct.store(A_reduced, index=(pid, ), tile=result)
if __name__ == "__main__":
main()
b) As M increases, the parallelization increases as more Streaming Multiprocessors (SM) are active. The theoratically performace maximum is when all SM’s are used.
The per-kernel-process load increases with K, because every thread needs to load more data from the memory and performs more operations. The increase is non-linear due to the requirement that tile sizes must be powers of 2.
Any K that is not a power of 2 requires zero-padding to the next power of 2, which introduces computational overhead.
Task 3: 4D Tensor Elementwise Addition
a) cuTile kernel that adds two 4D tensors A and B element-wise and stores the result in C. All tensors have identical shape and dimensions (M, N, K, L).
import torch
import cuda.tile as ct
def main():
M, N, K, L = 16, 128, 16, 128
size = (M, N, K, L)
A = torch.randn(size, device='cuda')
B = torch.randn(size, device='cuda')
C_kl = torch.empty(size, device='cuda')
C_mn = torch.empty(size, device='cuda')
grid_kl = (M, N)
grid_mn = (K, L)
ct.launch(torch.cuda.current_stream().cuda_stream,
grid_kl,
tensor_add_KL,
(A, B, C_kl, K, L),)
ct.launch(torch.cuda.current_stream().cuda_stream,
grid_mn,
tensor_add_MN,
(A, B, C_mn, M, N),)
expected = A + B
assert torch.allclose(C_kl, expected), "Task 3 KL failed: C_kl does not match expected result!"
assert torch.allclose(C_mn, expected), "Task 3 MN failed: C_mn does not match expected result!"
def tensor_add(A, B, C, index, shape):
A_block = ct.load(
A,
index=index,
shape=shape,
)
B_block = ct.load(
B,
index=index,
shape=shape,
)
result = A_block + B_block
ct.store(C, index=index, tile=result)
@ct.kernel
def tensor_add_KL(A, B, C, K: ct.Constant[int], L: ct.Constant[int]):
bid_m = ct.bid(0)
bid_n = ct.bid(1)
# Each block processes the full (K, L) sub-tensor at a specific (m, n)
index = (bid_m, bid_n, 0, 0)
shape = (1, 1, K, L)
tensor_add(A, B, C, index, shape)
@ct.kernel
def tensor_add_MN(A, B, C, M: ct.Constant[int], N: ct.Constant[int]):
bid_k = ct.bid(0)
bid_l = ct.bid(1)
# Each block processes the full (M, N) sub-tensor at a specific (k, l)
index = (0, 0, bid_k, bid_l)
shape = (M, N, 1, 1)
tensor_add(A, B, C, index, shape)
if __name__ == "__main__":
main()
b) Benchmark
import triton
import torch
import cuda.tile as ct
from task3 import tensor_add_KL, tensor_add_MN
M, N, K, L = 16, 128, 16, 128
size = (M, N, K, L)
def main():
global A, B, C
A = torch.randn(size, device='cuda')
B = torch.randn(size, device='cuda')
C = torch.empty(size, device='cuda')
t = triton.testing.do_bench(tensor_add_KL_benchmark)
print(f"tensor_add_KL benchmark: {t:.2f} ms")
C = torch.empty(size, device='cuda')
t = triton.testing.do_bench(tensor_add_MN_benchmark)
print(f"tensor_add_MN benchmark: {t:.2f} ms")
def tensor_add_KL_benchmark():
grid_kl = (M, N)
ct.launch(torch.cuda.current_stream().cuda_stream,
grid_kl,
tensor_add_KL,
(A, B, C, K, L),)
def tensor_add_MN_benchmark():
grid_mn = (K, L)
ct.launch(torch.cuda.current_stream().cuda_stream,
grid_mn,
tensor_add_MN,
(A, B, C, M, N),)
if __name__ == "__main__":
main()
Output:
tensor_add_KL benchmark: 0.39 ms
tensor_add_MN benchmark: 0.67 ms
The tensor_add_KL kernel is faster than the tensor_add_MN kernel. This is because the data accessed per kernel program is continuous in memory.
Task 4: Benchmarking Bandwidth
a) cuTile kernel that copies a 2D matrix of shape (M,N)
import torch
import cuda.tile as ct
# Note: *args will prevent positional arguments
def main(*args, M = 2048, N = 16, tile_M = 64, tile_N = None, dtype=torch.float32):
if tile_N is None:
tile_N = N
A = torch.randn((M, N), device='cuda', dtype=dtype)
B = torch.empty_like(A, device='cuda', dtype=dtype)
assert M % tile_M == 0, "M must be divisible by tile_M"
assert N % tile_N == 0, "N must be divisible by tile_N"
grid = (M // tile_M, N // tile_N)
ct.launch(torch.cuda.current_stream().cuda_stream,
grid,
matrix_copy,
(A, B, tile_M, tile_N))
assert torch.allclose(B, A), "Task 4 failed: B does not match A!"
@ct.kernel
def matrix_copy(A, B, tile_M: ct.Constant[int], tile_N: ct.Constant[int]):
bid_m = ct.bid(0)
bid_n = ct.bid(1)
index = (bid_m, bid_n)
A_block = ct.load(
A,
index=index,
shape=(tile_M, tile_N),
)
ct.store(B, index=index, tile=A_block)
if __name__ == "__main__":
main()
b) Benchmarking
import triton
import matplotlib.pyplot as plt
from pathlib import Path
import torch
from task4 import main as main_task4
def main():
N = [16, 32, 64, 128, 256, 512, 1024, 2048]
M = 2048
dtype = torch.float32
bandwidths = []
for n in N:
t = triton.testing.do_bench(lambda: main_task4(M=M, N=n, tile_M=64, tile_N=n, dtype=dtype))
print(f"matrix_copy benchmark for N={n}: {t:.2f} ms")
element_size = torch.tensor([], dtype=dtype).element_size()
bandwidth = 2 * M * n * element_size / (t * 1e6) # GB/s
bandwidths.append(bandwidth)
# plot results
plt.plot(N, bandwidths, marker='o')
plt.xlabel('N (number of columns)')
plt.ylabel('Bandwidth (GB/s)')
plt.title('matrix_copy Benchmark: Bandwidth vs N')
plt.xscale('log', base=2)
plt.xticks(N)
plt.grid(True)
file_dir = Path(__file__).parent
plt.savefig(file_dir / 'task4_benchmark.png')
if __name__ == "__main__":
main()
Output:
matrix_copy benchmark for N=16: 0.08 ms
matrix_copy benchmark for N=32: 0.09 ms
matrix_copy benchmark for N=64: 0.10 ms
matrix_copy benchmark for N=128: 0.12 ms
matrix_copy benchmark for N=256: 0.16 ms
matrix_copy benchmark for N=512: 0.28 ms
matrix_copy benchmark for N=1024: 0.62 ms
matrix_copy benchmark for N=2048: 1.32 ms
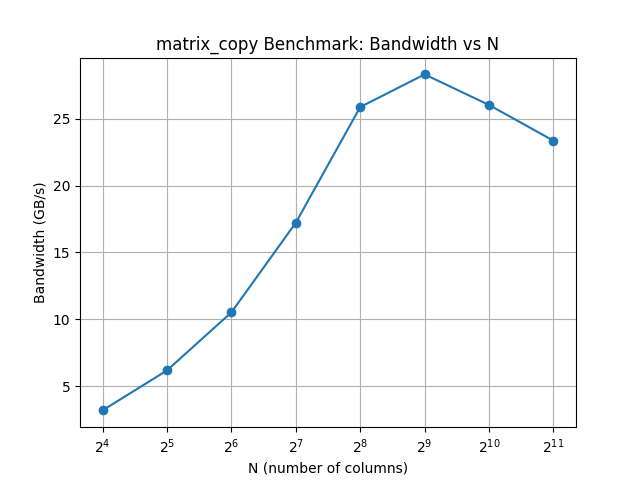 Because the bandwidth was still increasing at
Because the bandwidth was still increasing at N=128, we included a few more points up to N=2048 to show the trend more clearly. The bandwidth increases as N increases, which is expected because larger matrices allow for better utilization of the GPU’s memory bandwidth. However, the bandwidth reaches its peak at around N=512 and then starts to decrease. Probably this is the point we reach hardware limits of the GPU.