Assignment 04: Tensor Contractions on GPUs
Task 1: Tiled Contraction Kernel Variants
a) Classify all dimensions in the einsum string eabklxy, ecklyz -> eabcxz.
$$M = abx, N = cz, K = kly, C = e$$
b) Implement a cuTile kernel that computes the contraction eabklxy, ecklyz -> eabcxz. Use dimensions xyz as your GEMM dimensions. Sequentialize all other K-dimensions, parallelize the remaining dimensions. The kernel should work with arbitrary dimension sizes. You can hand them to your kernel as function arguments.
@ct.kernel
def contraction(A, B, C, k: ct.Constant[int], l: ct.Constant[int], x: ct.Constant[int], y: ct.Constant[int], z: ct.Constant[int], c: ct.Constant[int]):
e_it = ct.bid(0)
a_it = ct.bid(1)
bc_it = ct.bid(2)
b_it = bc_it // c
c_it = bc_it % c
acc = ct.zeros((x, z), dtype=ct.float32)
for k_it in range(k):
for l_it in range(l):
A_ = ct.load(
A,
index=(e_it,a_it,b_it,k_it,l_it,0,0),
shape=(1,1,1,1,1,x,y),
padding_mode=ct.PaddingMode.ZERO
)
A_ = ct.reshape(A_, (x, y))
B_ = ct.load(
B,
index=(e_it,c_it,k_it,l_it,0,0),
shape=(1,1,1,1,y,z),
padding_mode=ct.PaddingMode.ZERO
)
B_ = ct.reshape(B_, (y, z))
acc += ct.matmul(A_, B_)
acc = ct.astype(acc, ct.float16)
acc = ct.reshape(acc, (1,1,1,1,x,z))
ct.store(C, index=(e_it,a_it,b_it,c_it,0,0), tile=acc)
c) Implement a cuTile kernel that computes the contraction eabklxy, ecklyz -> eabcxz. Use dimensions xyz as your GEMM dimensions. Sequentialize all other K-dimensions, as well as the b dimension. Parallelize the remaining dimensions. The kernel should work with arbitrary dimension sizes. You can hand them to your kernel as function arguments.
@ct.kernel
def contraction(A, B, C, k: ct.Constant[int], l: ct.Constant[int], x: ct.Constant[int], y: ct.Constant[int], z: ct.Constant[int], b: ct.Constant[int]):
e_it = ct.bid(0)
a_it = ct.bid(1)
c_it = ct.bid(2)
for b_it in range(b):
acc = ct.zeros((x, z), dtype=ct.float32)
for k_it in range(k):
for l_it in range(l):
A_ = ct.load(
A,
index=(e_it,a_it,b_it,k_it,l_it,0,0),
shape=(1,1,1,1,1,x,y),
padding_mode=ct.PaddingMode.ZERO
)
A_ = ct.reshape(A_, (x, y))
B_ = ct.load(
B,
index=(e_it,c_it,k_it,l_it,0,0),
shape=(1,1,1,1,y,z),
padding_mode=ct.PaddingMode.ZERO
)
B_ = ct.reshape(B_, (y, z))
acc+= ct.matmul(A_, B_)
acc = ct.astype(acc, ct.float16)
acc = ct.reshape(acc, (1,1,1,1,x,z))
ct.store(C, index=(e_it,a_it,b_it,c_it,0,0), tile=acc)
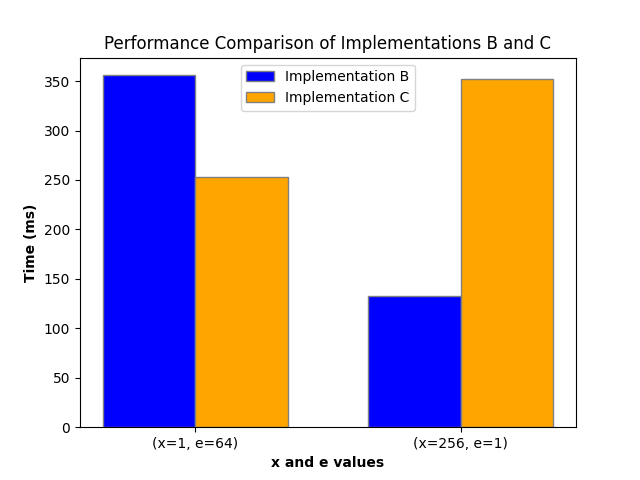
Find one configuration (dimension sizes) where your kernel from b) performs better and one configuration where your new kernel from c) performs better.
Configuration:
a = 64
c = 64
k = 1
l = 16
y = 32
z = 32
b = 8
d) Implement a cuTile kernel that computes the contraction eabklxy, ecklyz -> eabcxz. Use dimensions xyzl as your GEMM dimensions by permuting the input tiles of the ct.mma instruction, as well as reshaping so that y and l are merged.
@ct.kernel
def contraction(A, B, C, k: ct.Constant[int], l: ct.Constant[int], x: ct.Constant[int], y: ct.Constant[int], z: ct.Constant[int], c: ct.Constant[int]):
e_it = ct.bid(0)
a_it = ct.bid(1)
bc_it = ct.bid(2)
b_it = bc_it // c
c_it = bc_it % c
acc = ct.zeros((x, z), dtype=ct.float32)
for k_it in range(k):
A_ = ct.load(
A,
index=(e_it,a_it,b_it,k_it,0,0,0),
shape=(1,1,1,1,l,x,y),
padding_mode=ct.PaddingMode.ZERO
)
A_ = ct.permute(A_, (0,1,2,3,5,4,6))
A_ = ct.reshape(A_, (x, y*l))
B_ = ct.load(
B,
index=(e_it,c_it,k_it,0,0,0),
shape=(1,1,1,l,y,z),
padding_mode=ct.PaddingMode.ZERO
)
B_ = ct.reshape(B_, (y*l, z))
acc += ct.matmul(A_, B_)
acc = ct.astype(acc, ct.float16)
acc = ct.reshape(acc, (1,1,1,1,x,z))
ct.store(C, index=(e_it,a_it,b_it,c_it,0,0), tile=acc)
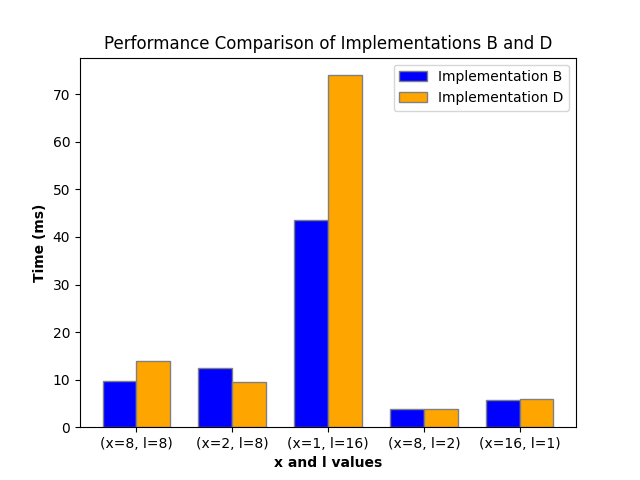
Find one configuration (dimension sizes) where your kernel from b) performs better and one configuration where your new kernel from d) performs better.
Configuration:
a = 16
c = 16
k = 8
e = 16
y = 16
z = 16
b = 16
e) Implement a cuTile kernel that computes the contraction eabklxy, ecklyz -> eabcxz. Use dimensions exyz as your GEMM dimensions, meaning that you perform a 3D ct.mma inside the kernel. Sequentialize all other K-dimensions, parallelize the remaining dimensions. The kernel should work with arbitrary dimension sizes.
@ct.kernel
def contraction(A, B, C, k: ct.Constant[int], l: ct.Constant[int], x: ct.Constant[int], y: ct.Constant[int], z: ct.Constant[int], c: ct.Constant[int], e: ct.Constant[int]):
a_it = ct.bid(0)
b_it = ct.bid(1)
c_it = ct.bid(2)
acc = ct.zeros((e, x, z), dtype=ct.float32)
for k_it in range(k):
for l_it in range(l):
A_ = ct.load(
A,
index=(0,a_it,b_it,k_it,l_it,0,0),
shape=(e,1,1,1,1,x,y),
padding_mode=ct.PaddingMode.ZERO
)
A_ = ct.reshape(A_, (e, x, y))
B_ = ct.load(
B,
index=(0,c_it,k_it,l_it,0,0),
shape=(e,1,1,1,y,z),
padding_mode=ct.PaddingMode.ZERO
)
B_ = ct.reshape(B_, (e, y, z))
acc += ct.matmul(A_, B_)
acc = ct.astype(acc, ct.float16)
acc = ct.reshape(acc, (e,1,1,1,x,z))
ct.store(C, index=(0,a_it,b_it,c_it,0,0), tile=acc)
Tensor shapes: A: (16, 15, 104, 33, 5, 4, 16), B: (16, 41, 33, 5, 16, 16), C: (16, 15, 104, 41, 4, 16)
1_b Time: 294.75 ms
1_e Time: 1310.34 ms
Task 2: Kernel Fusion
a) Implement a cuTile kernel for the contraction eabklxy, ecklyz -> eabcxz where you fuse an elementwise tensor multiplication of a tensor D of shape eabcxz with the output tensor. The output tensor can be overwritten by the multiplication.
@ct.kernel
def fused_contraction_multiplication(A, B, C, D, k: ct.Constant[int], l: ct.Constant[int], x: ct.Constant[int], y: ct.Constant[int], z: ct.Constant[int], c: ct.Constant[int]):
e_it = ct.bid(0)
a_it = ct.bid(1)
bc_it = ct.bid(2)
b_it = bc_it // c
c_it = bc_it % c
acc = ct.zeros((x, z), dtype=ct.float32)
for k_it in range(k):
for l_it in range(l):
A_ = ct.load(
A,
index=(e_it,a_it,b_it,k_it,l_it,0,0),
shape=(1,1,1,1,1,x,y),
padding_mode=ct.PaddingMode.ZERO
)
A_ = ct.reshape(A_, (x, y))
B_ = ct.load(
B,
index=(e_it,c_it,k_it,l_it,0,0),
shape=(1,1,1,1,y,z),
padding_mode=ct.PaddingMode.ZERO
)
B_ = ct.reshape(B_, (y, z))
acc += ct.matmul(A_, B_)
D_ = ct.load(
D,
index=(e_it,a_it,b_it,c_it,0,0),
shape=(1,1,1,1,x,z),
padding_mode=ct.PaddingMode.ZERO
)
acc *= D_
acc = ct.reshape(acc, (1,1,1,1,x,z))
acc = ct.astype(acc, ct.float16)
ct.store(C, index=(e_it,a_it,b_it,c_it,0,0), tile=acc)
b) Implement a kernel that computes the elementwise multiplication only. Compare runtime results of your fused kernel with sequentially calling the cuTile contraction kernel, then the elementwise multiplication. Choose tensor sizes such that the FLOP count of the contraction is similar to a 2048x2048x2048 matrix multiplication.
@ct.kernel
def multiply(C, D, c: ct.Constant[int], x: ct.Constant[int], z: ct.Constant[int]):
e_it = ct.bid(0)
a_it = ct.bid(1)
bc_it = ct.bid(2)
b_it = bc_it // c
c_it = bc_it % c
D_ = ct.load(
D,
index=(e_it,a_it,b_it,c_it,0,0),
shape=(1,1,1,1,x,z),
padding_mode=ct.PaddingMode.ZERO
)
C_ = ct.load(
C,
index=(e_it,a_it,b_it,c_it,0,0),
shape=(1,1,1,1,x,z),
padding_mode=ct.PaddingMode.ZERO
)
acc = C_ * D_
ct.store(C, index=(e_it,a_it,b_it,c_it,0,0), tile=acc)
Output:
Tensor shapes: A: (1, 16, 16, 16, 16, 8, 8), B: (1, 32, 16, 16, 8, 64), C: (1, 16, 16, 32, 8, 64)
Required memory: 0.02 GiB
Execution time of fused kernel: 5.72 ms
Execution time of separate kernels: 5.23 ms
Success!
The fused kernel is actually slower than the separate kernels in this case. This is likely because the fused kernel has a higher register pressure, which can lead to lower occupancy and thus worse performance. Additionally, the fused kernel may not be able to fully utilize the GPU’s resources due to the increased complexity of the operations being performed. In contrast, the separate kernels can be optimized independently, allowing for better performance in this specific case.
Task 3: GEMM Dimension Size Sweep
a) Implement a contraction kernel that computes the contraction ackm, bcnk -> abnm. Assume fixed dimension sizes |a| = 16, |b| = 16, and |c| = 32. The kernel should be able to handle arbitrary sizes for dimensions mnk.
@ct.kernel
def contraction(A, B, C, k: ct.Constant[int], m: ct.Constant[int], n: ct.Constant[int], c: ct.Constant[int]):
a_it = ct.bid(0)
b_it = ct.bid(1)
acc = ct.zeros((n, m), dtype=ct.float32)
for c_it in range(c):
for k_it in range(k):
A_ = ct.load(
A,
index=(a_it, c_it, k_it, 0),
shape=(1, 1, 1, m),
padding_mode=ct.PaddingMode.ZERO
)
A_ = ct.reshape(A_, (1, m))
B_ = ct.load(
B,
index=(b_it, c_it , 0, k_it),
shape=(1, 1, n, 1),
padding_mode=ct.PaddingMode.ZERO
)
B_ = ct.reshape(B_, (n, 1))
acc += ct.matmul(B_, A_)
acc = ct.astype(acc, ct.float16)
acc = ct.reshape(acc, (1, 1, n, m))
ct.store(C, index=(a_it, b_it , 0, 0), tile=acc)
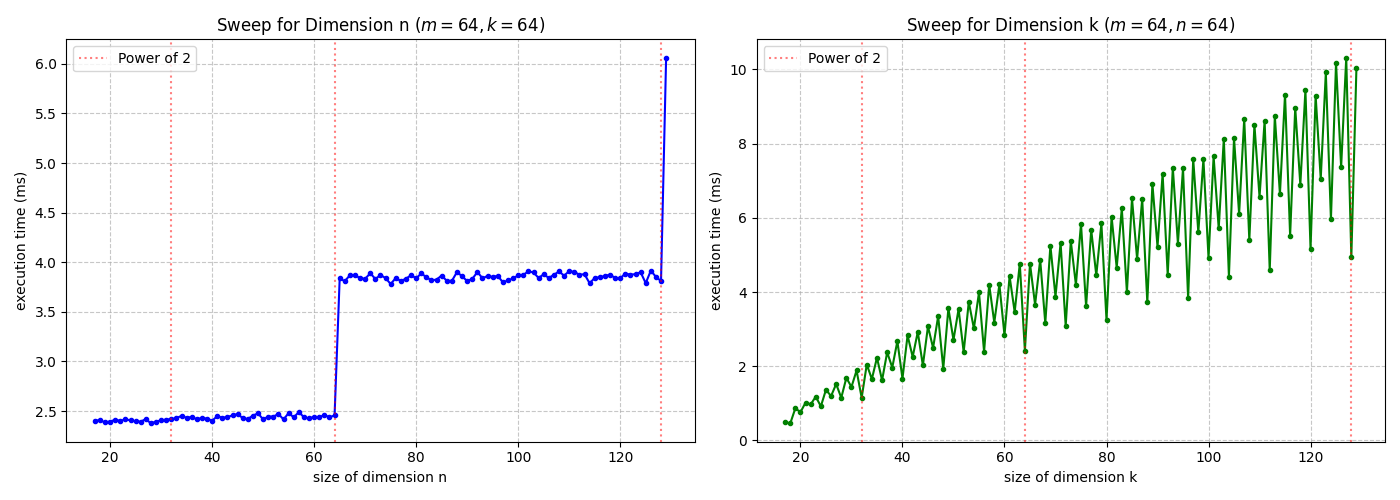
b) Perform the following benchmarks, visualize your results and explain your findings:
Scaling the k-dimension increases the computational operations, whereas expanding the n-dimension grows the DRAM utilization and traffic. Even Numbers of the k-dimension are faster then odd Numbers. Because the n dimension is padded to the next power of two, performance steps occur only when the dimension size crosses a power-of-two threshold (e.g., moving from 64 to 65), as this triggers a doubling of the allocated workspace. For the same increase in k and m, the k-dimension requieres a higher penalty for the execution time. That is because k is an contraction dimension and creates more computational overhead by triggering more load and matmul operations.