Assignment 05: Contraction Interface and L2 Optimization
In this assignment you will build a high-level configuration interface for tensor contractions, implement an optimizer that manipulates those configurations, and use it to derive and benchmark an L2-optimized cuTile kernel.
All code should be written in src/.
We assume the following import conventions:
import cuda.tile as ct
import cupy as cp
import torch
import triton
from dataclasses import dataclass, field
Use FP16 data type for tensor inputs and outputs, accumulate in FP32. We assume row-major order for all tensors.
Task 1: Config Class
Define the following Python types that together represent a tensor contraction configuration as introduced in the lecture.
a) Define enumeration types (e.g. using Python’s enum.Enum or simple class constants) for:
DimType:M,N,K,CExecType:SEQ,PAR,PRIMPrimType:GEMM,BGEMMLastType:NONE,ELWISE_MULFirstType:ZERODataType:FLOAT16,FLOAT32
b) Define a Config dataclass with the following fields, matching the interface
shown in the lecture:
Field |
Type |
Description |
|---|---|---|
|
|
Numeric precision of the operands |
|
|
Main (B)GEMM primitive used inside the kernel |
|
|
Optional elementwise operation applied after the accumulation |
|
|
Initialization of the accumulator |
|
|
Per-dimension index type |
|
|
Per-dimension execution strategy |
|
|
Per-dimension size |
|
|
Per-tensor, per-dimension stride (one inner list per tensor) |
Task 2: Generating a Basic Config
Write a function generate_config that takes an einsum string and a list of shapes for the input tensors (the output shape is implied by the einsum) and returns a basic Config.
Requirements:
Classify each dimension index automatically by inspecting in which tensors it appears.
Compute strides for every tensor assuming row-major layout. A stride of
0indicates that the dimension does not appear in that tensor.Set all
exec_typestoSEQ.Set
data_type = DataType.FLOAT16,prim_main = PrimType.GEMM,prim_last = LastType.NONE,prim_first = FirstType.ZERO.
Task 3: Optimizer Class
Implement a class Optimizer that wraps a Config and exposes methods to transform it.
a) Implement the function split_dim(dim_id: int, outer_size: int, inner_size: int).
It splits one dimension into two. outer_size * inner_size must equal the original size; raise a ValueError otherwise.
After splitting:
Insert two new dimensions at the position of the original dimension.
The outer dimension (left) gets
size = outer_size.The inner dimension (right) gets
size = inner_size.Strides have to be updated accordingly.
Both new dimensions inherit
dim_typeandexec_typefrom the original.
b) Implement the function fuse_dims(dim_id_a: int, dim_id_b: int).
Fuse two dimensions into a single one. Two dimensions can only be fused if they are adjacent in every tensor they both appear in, i.e., the two dimensions are contiguous in memory (stride[a] == stride[b] * size[b] or stride[a] * size[a] == stride[b]) in every tensor.
Check this condition for all tensors before performing the fusion. Raise a descriptive ValueError if the check fails.
After a valid fusion:
The new size is
size[a] * size[b].Update the strides lists accordingly.
The fused dimension inherits the
dim_typeandexec_typeofdim_id_a.Remove one dimension from all lists.
c) Implement the function permute_dims(permutation: list[int]).
Reorder all per-dimension lists (dim_types, exec_types, dim_sizes, and each tensor’s strides list) according to permutation, following the syntax of torch.permute.
d) Implement the function make_executable().
Set exec types and permute the config’s dimensions so that the config becomes executable via cuTile. Use the parallel execution type where possible. Test the resulting configuration with your verify() function from e).
e) Implement the function verify().
Check that the current configuration is executable. Raise a descriptive ValueError for each violated condition:
No
K-dimension may haveexec_type = PAR.All dimensions with
exec_type = SEQmust appear to the left of all dimensions withexec_type = PRIMin the config.All dimensions with
exec_type = PARmust appear to the left of all dimensions withexec_type = SEQin the config.The rightmost dimensions must be
PRIMand thePRIMdimensions must include at least one dimension of each typeM,N, andK.
Task 4: L2-Optimized Batched Contraction
NOTE: wenn ab 5 dimensionen performance schlechter, dann siehe assume_div_by hints der optional task in week 2.
Consider the batched matrix multiplication expressed as cmk, ckn -> cmn with dimension sizes $|c| = 4$, $|m| = |n| = |k| = 4096$.
a) Use your generate_config function from Task 2 to produce the initial Config for this contraction. Report the resulting config.
Output:
Config(
data_type=DataType.FLOAT16,
prim_main=PrimType.GEMM,
prim_last=LastType.NONE,
prim_first=FirstType.ZERO,
dim_types=[<DimType.C: 3>, <DimType.M: 0>, <DimType.K: 2>, <DimType.N: 1>],
exec_types=[<ExecType.SEQ: 0>, <ExecType.SEQ: 0>, <ExecType.SEQ: 0>, <ExecType.SEQ: 0>],
dim_sizes=[4, 4096, 4096, 4096],
strides=[[16777216, 4096, 1, 0], [16777216, 0, 4096, 1], [16777216, 4096, 0, 1]]
)
b) Use your Optimizer and the implemented functions from Task 3 to transform the basic config into an L2-optimized one, following the general L2-reuse pattern from the lecture.
config.dim_sizes = [ [...], |m_l2|, |n_l2|, |m_prim|, |n_prim|, |k_prim|]
Choose the sizes for m_l2, m_prim, n_l2, n_prim and justify your choice with respect to L2 cache reuse.
Report the final config.
prim sizes
First we want to choose the optimal m_prim, n_prim, k_prim sizes of one mma instruction.
We want to fit as many primitive operations of a matrix multiplication into one operation of mma as possible which is m_prim * n_prim * k_prim. In one mma operation the maximal memory is th max shared memory per block, which is 48 KiB for our machine. Using FP32 (4 bytes) for accumulation and FP16 (2 bytes) for inputs, the required memory for one mma is mma_size = (2 * m_prim * k_prim + 2 * k_prim * n_prim + 4 * m_prim * n_prim) bytes.
Therefore want to maximize m_prim * n_prim * k_prim s.t. mma_size = max_shared_memory_per_block.
Assuming m_prim = n_prim due to symmetry, leaves the optimization problem:
max m_prim^2 * k_prim s.t. 4 * m_prim * k_prim + 4 * m_prim^2 = max_shared_memory_per_block
This is solved for m_prim = sqrt(max_shared_memory_per_block/12)
In the case of 48 KiB of shared memory, m_prim = n_prim = 64 and k_prim = max_shared_memory_per_block / (4 * m_prim) - m_prim = 128 is optimal.
L2 sizes
Next we want to choose m_l2 and n_l2 such that they fit into the L2 cache. The size of the L2 cache on our machine is 24MiB. Each kernel block loads k//k_prim=32 tiles of A and B of size k_prim * m_prim and k_prim * n_prim respectively with 128*64*2 = 16384 bytes. So in total we can load 24 MiB / 16384 bytes = 1536 tiles of A and B into the L2 cache, resulting in 1536 / 32 = 48 kernel blocks fitting into the L2 cache. So we can choose m_l2 = n_l2 = 24 to have 48 blocks working on different m_l2, n_l2 tiles while reusing the same k_outer tiles in L2. Another option is m_l2 = 32 and n_l2 = 16, also resulting in 48 blocks in L2. This might be better since both are a power of two.
c) Implement the kernel
Implement a cuTile kernel that computes cmk, ckn -> cmn following your optimized config from b). Verify correctness of your kernel.
d) Use triton.testing.do_bench (or a similar benchmark function provided by cuTile/Torch) to measure the average kernel runtime. Report the achieved performance in TFLOPS.
Compare the performance of your L2-optimized kernel to a baseline kernel that maps BIDs in plain row-major order over (c, m, n) without any splitting or permuting. Report your findings.
def task_c_and_d():
c = 4
n = m = k = 4096
# optimal config from b:
m_prim = n_prim = 64
k_prim = 128
m_l2 = 16
n_l2 = 32
k_outer = k // k_prim
m_outer = m // (m_l2 * m_prim)
n_outer = n // (n_l2 * n_prim)
# c,m_outer,n_outer,m_l2,n_l2,k_outer,m_prim,n_prim,k_prim
A = torch.randn((c,m_outer,m_l2,k_outer,m_prim,k_prim), device='cuda', dtype=torch.float16)
B = torch.randn((c,n_outer,n_l2,k_outer,n_prim,k_prim), device='cuda', dtype=torch.float16)
C = torch.empty((c,m_outer,n_outer,m_l2,n_l2,m_prim,n_prim), device='cuda', dtype=torch.float16)
grid = (c, m_outer*n_outer, m_l2*n_l2)
args = (A, B, C, n_outer, n_l2, m_prim, n_prim, k_prim, k_outer, m_l2)
ms = triton.testing.do_bench(lambda: ct.launch(torch.cuda.current_stream(), grid, multiply, args))
tflops = 2 * (n * m * k * c) / (ms / 1000) / (10**12)
print(f"Execution time of optimized kernel: {ms:.2f} ms")
print(f"TFLOPS of optimized kernel: {tflops:.2f}")
# permute to original shape
A = A.permute(0, 1, 2, 4, 3, 5).reshape((c,m,k))
B = B.permute(0, 3, 5, 1, 2, 4).reshape((c,k,n))
C = C.permute(0, 1, 3, 5, 2, 4, 6).reshape((c,m,n))
expected = torch.einsum("cmk, ckn -> cmn", A, B)
assert torch.allclose(C, expected, atol=1e-1), "The result of c) is incorrect!"
# no swizzling
C = torch.empty((c,m,n), device='cuda', dtype=torch.float16)
args_baseline = (A, B, C, m_prim, n_prim, k_prim, k//k_prim)
grid_baseline = (c, m//m_prim, n//n_prim)
ms_baseline = triton.testing.do_bench(lambda: ct.launch(torch.cuda.current_stream(), grid_baseline, baseline_multiply, args_baseline))
assert torch.allclose(C, expected, atol=1e-1), "The result of baseline is incorrect!"
tflops_baseline = 2 * (n * m * k * c) / (ms_baseline / 1000) / (10**12)
print(f"Execution time of baseline kernel: {ms_baseline:.2f} ms")
print(f"TFLOPS of baseline kernel: {tflops_baseline:.2f}")
plot_results(tflops, tflops_baseline)
@ct.kernel
def multiply(A, B, C, n_outer: ct.Constant[int], n_l2: ct.Constant[int], m_prim: ct.Constant[int], n_prim: ct.Constant[int], k_prim: ct.Constant[int], k_outer: ct.Constant[int], m_l2: ct.Constant[int]):
c_it = ct.bid(0)
mn_outer_it = ct.bid(1)
mn_l2_it = ct.bid(2)
m_outer_it = mn_outer_it // n_outer
n_outer_it = mn_outer_it % n_outer
m_l2_it = mn_l2_it // n_l2
n_l2_it = mn_l2_it % n_l2
# m_it = m_outer_it * m_l2 + m_l2_it
# n_it = n_outer_it * n_l2 + n_l2_it
acc = ct.zeros((m_prim, n_prim), dtype=ct.float32)
for k_it in range(k_outer):
# c,m_outer,n_outer,m_l2,n_l2,k_outer,m_prim,n_prim,k_prim
A_tile = ct.load(
A,
index=(c_it,m_outer_it,m_l2_it,k_it,0,0),
shape=(1,1,1,1,m_prim,k_prim),
).reshape((m_prim, k_prim))
B_tile = ct.load(
B,
index=(c_it,n_outer_it,n_l2_it,k_it,0,0),
shape=(1,1,1,1,n_prim,k_prim),
).reshape((n_prim,k_prim)).transpose()
acc = ct.mma(A_tile, B_tile, acc=acc)
C_ = acc.astype(ct.float16).reshape((1,1,1,1,1,m_prim,n_prim))
ct.store(C, index=(c_it,m_outer_it,n_outer_it,m_l2_it,n_l2_it,0,0), tile=C_)
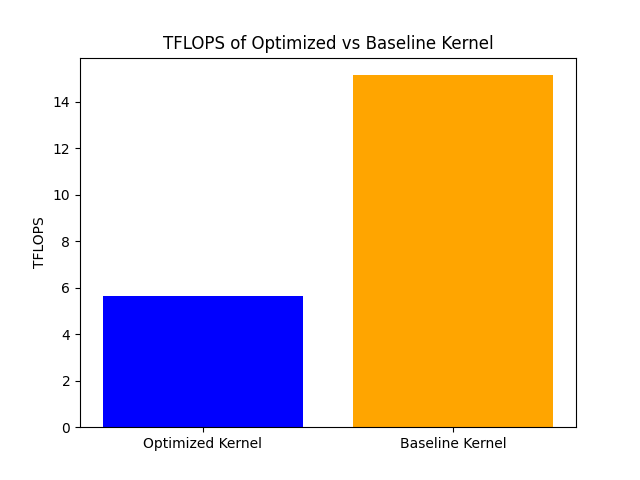
The optimized kernel achieves 5.66 TFLOPS, while the baseline kernel achieves 15.14 TFLOPS. The optimized kernel is slower than the baseline kernel, which is unexpected. One possible reason for this could be that the chosen tile sizes for L2 optimization are not optimal (maybe a wrong assumption in b). Another reason could be that the overhead of managing the more complex tiling and scheduling in the optimized kernel outweighs the benefits of improved cache reuse. Further analysis and tuning of the tile sizes and scheduling strategy may be necessary to achieve better performance with the optimized kernel.