Assignment 03: Matrix Multiplication with cuTile
The file assignments/03_assignment/src/__main__.py contains the main function that runs all the tasks for this assignment. Each task is implemented in a separate file in the same directory. The results of each task are printed to the console when the main function is executed.
Task 1: FP32 vs FP16 Performance
Output:
16bit TFLOPs: 1.1449544748761349
32bit TFLOPs: 0.019409971572566145
import cuda.tile as ct
import cupy as cp
from numpy.strings import index
import torch
import triton
def main():
inner_size = 4096
A = torch.randn((64, inner_size), device='cuda', dtype=torch.float16)
B = torch.randn((inner_size, 64), device='cuda', dtype=torch.float16)
C = torch.empty((64, 64), device='cuda', dtype=torch.float32)
grid = (1, )
torch.cuda.init()
ct.launch(torch.cuda.current_stream(), grid, kernel_fp16, (A, B, C))
torch.cuda.synchronize()
expected = torch.empty((64, 64), device='cuda', dtype=torch.float16)
torch.matmul(A, B, out=expected)
expected = expected.to(torch.float32) # Convert to float32 for comparison
assert torch.allclose(C, expected, atol=1e-1), "The result is incorrect!"
@ct.kernel
def kernel_fp16(A, B, C):
m_tile=64
n_tile=64
k_tile=64
result = ct.load(C, index=(0, 0), shape=(m_tile, n_tile))
for i in range(0, A.shape[0] // m_tile):
for j in range(0, B.shape[1] // n_tile):
for k in range(0, A.shape[1] // k_tile):
A_block = ct.load(A, index=(i, k), shape=(m_tile, k_tile))
B_block = ct.load(B, index=(k, j), shape=(k_tile, n_tile))
result = ct.mma(A_block, B_block, acc=result)
ct.store(C, index=(0, 0), tile=result)
if __name__ == "__main__":
main()
Task 2: Simple Matrix Multiplication Kernel
Output:
16bit TFLOPs: 1.1449544748761349
32bit TFLOPs: 0.019409971572566145
import math
import cuda.tile as ct
import cupy as cp
from numpy.strings import index
import torch
import triton
def main():
M = 321
N = 123
K = 23
m_tile=64
n_tile=32
k_tile=128
M_padded = int(2**math.ceil(math.log2(max(M, m_tile))))
N_padded = int(2**math.ceil(math.log2(max(N, n_tile))))
K_padded = int(2**math.ceil(math.log2(max(K, k_tile))))
A = torch.randn((M, K), device='cuda', dtype=torch.float16)
B = torch.randn((K, N), device='cuda', dtype=torch.float16)
C = torch.empty((M, N), device='cuda', dtype=torch.float32)
grid = (math.ceil(M_padded / m_tile) * math.ceil(N_padded / n_tile), )
torch.cuda.init()
ct.launch(torch.cuda.current_stream(), grid, kernel_fp16, (A, B, C, m_tile, n_tile, k_tile, M_padded, N_padded, K_padded))
torch.cuda.synchronize()
expected = torch.empty((M, N), device='cuda', dtype=torch.float16)
torch.matmul(A, B, out=expected)
expected = expected.to(torch.float32) # Convert to float32 for comparison
# print("Expected:\n", expected)
# print("Actual:\n", C)
assert torch.allclose(C, expected, atol=1e-1), "The result is incorrect!"
@ct.kernel
def kernel_fp16(A, B, C, m_tile: ct.Constant[int], n_tile: ct.Constant[int], k_tile: ct.Constant[int], M_padded: ct.Constant[int], N_padded: ct.Constant[int], K_padded: ct.Constant[int]):
bid = ct.bid(0)
bid_x = bid % (N_padded // n_tile)
bid_y = bid // (N_padded // n_tile)
result = ct.zeros((m_tile, n_tile), dtype=torch.float32)
for k in range(0, K_padded // k_tile):
A_block = ct.load(A, index=(bid_y , k), shape=(m_tile, k_tile), padding_mode=ct.PaddingMode.ZERO)
B_block = ct.load(B, index=(k, bid_x), shape=(k_tile, n_tile), padding_mode=ct.PaddingMode.ZERO)
result = ct.mma(A_block, B_block, acc=result)
# print("Result in kernel:\n", result)
ct.store(C, index=(bid_y, bid_x), tile=result)
if __name__ == "__main__":
main()
Task 3: Benchmarking the Matrix Multiplication Kernel
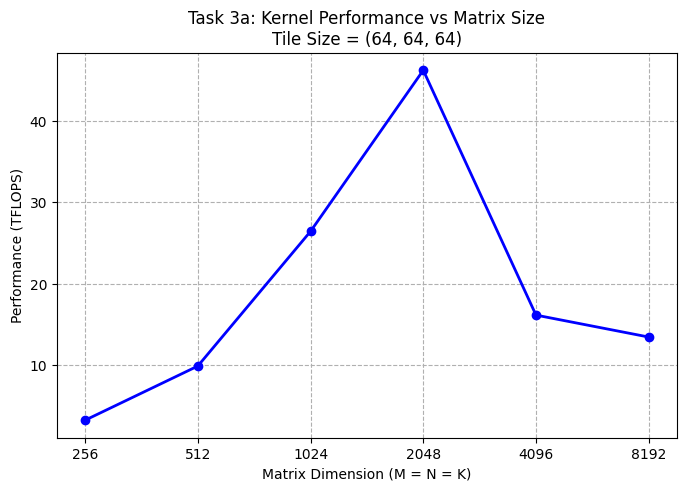
a) Benchmark your kernel with tile shapes (64, 64, 64) for square matrix multiplications of sizes:
b) Fix the matrix size at 2048 × 2048 × 2048, as well as 512 × 512 × 512, and benchmark all tile shape combinations (27 total):
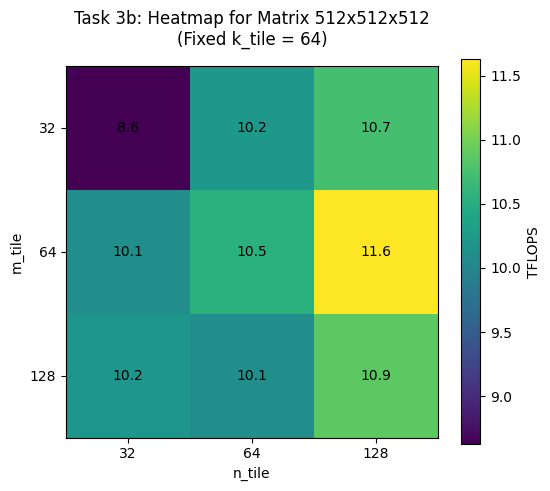
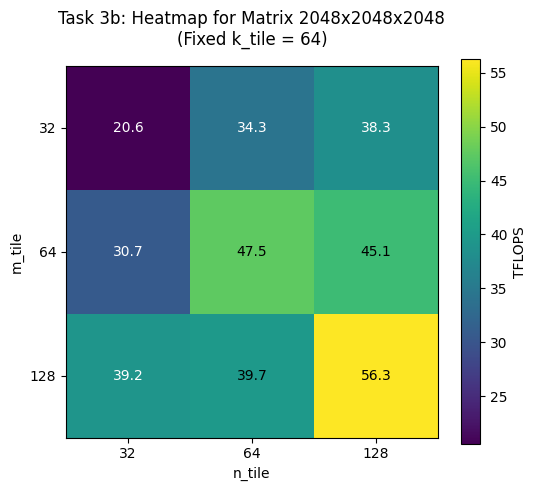
Output:
BEST tile shape for 512x512x512 is (128, 64, 128) achieving 12.07 TFLOPS
BEST tile shape for 2048x2048x2048 is (128, 128, 64) achieving 54.57 TFLOPS
Task 4: L2 Cache Optimization via Block Swizzling
@ct.kernel
def kernel_matmul_swizzle(A, B, C, tm: ct.Constant[int], tn: ct.Constant[int], tk: ct.Constant[int], grid_x, grid_y):
swizzle_size = 8
pid = ct.bid(0)
num_pid_in_block = swizzle_size * grid_y
block_index = (pid // num_pid_in_block)
begin_m = (block_index * swizzle_size)
swizzle = swizzle_size
if (begin_m + swizzle_size) > grid_x:
swizzle = grid_x - begin_m
index_m_temp = pid % swizzle
index_n_temp = pid // swizzle
index_n = index_n_temp % grid_y
index_m = begin_m + index_m_temp
num_tiles_k = ct.num_tiles(A, axis=1, shape=(tm, tk))
accumulator = ct.full((tm, tn), 0, dtype=ct.float32)
for k in range(num_tiles_k):
a = ct.load(A, index=(index_m, k), shape=(tm, tk), padding_mode=ct.PaddingMode.ZERO)
b = ct.load(B, index=(k, index_n), shape=(tk, tn), padding_mode=ct.PaddingMode.ZERO)
accumulator = ct.mma(a, b, accumulator)
ct.store(C, index=(index_m, index_n), tile=accumulator)
Output:
swizzle_kernel TFLOPs: 68.14132984785671
non_swizzle_kernel TFLOPs: 27.46563761972282
PIDs are mapped into horizontal ‘stripes’ across the output matrix. Each stripe consists of 8 rows. Within a stripe, the PIDs traverse the tiles column by column: the first 8 PIDs compute a vertical column of 8 tiles downwards. When the stripe is finished. The next stripe is computed, starting at row index 8. At the last stripe the remaining heiht of the stripe (the rows) are calculated dynamically, to prevent out-of-bounds memory accesses.
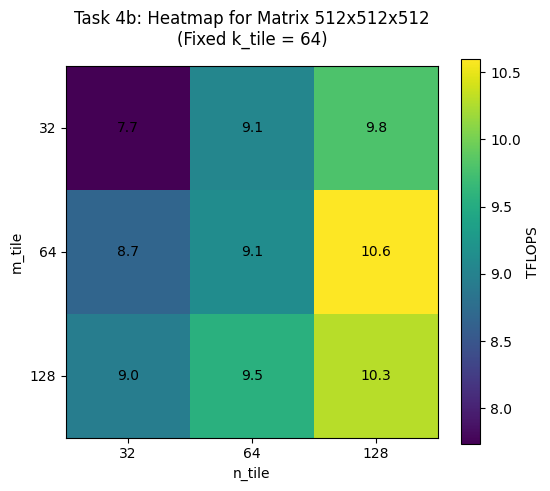
-> BEST tile shape for 512x512x512 is (128, 64, 32) achieving 10.77 TFLOPS
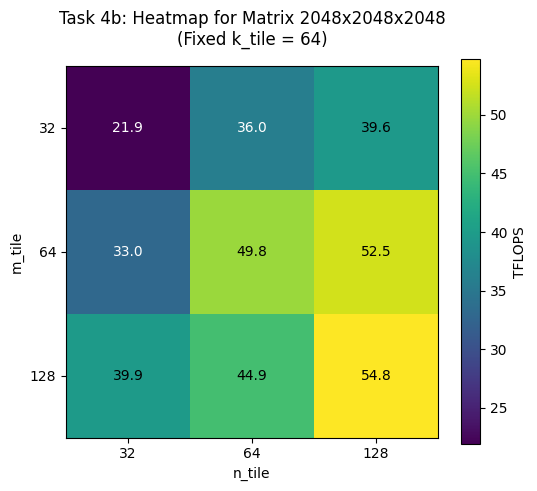
-> BEST tile shape for 2048x2048x2048 is (128, 128, 64) achieving 54.77 TFLOPS